今日值得关注的大模型前沿论文
JudgeBench:用于评估“LLM 法官”的评测基准
DeepSeek 推出统一多模态理解、生成自回归框架 Janus
OpenAI o1 模型推理模式的比较研究
首个“任意对任意”的真实世界多模态评估基准
上交大团队推出 MobA:由多模态大语言模型驱动的新型移动智能体
想要第一时间获取每日最新大模型热门论文?
点击阅读原文,查看“2024必读大模型论文”
ps:我们日常会分享日报、周报,后续每月也会出一期月报,敬请期待~
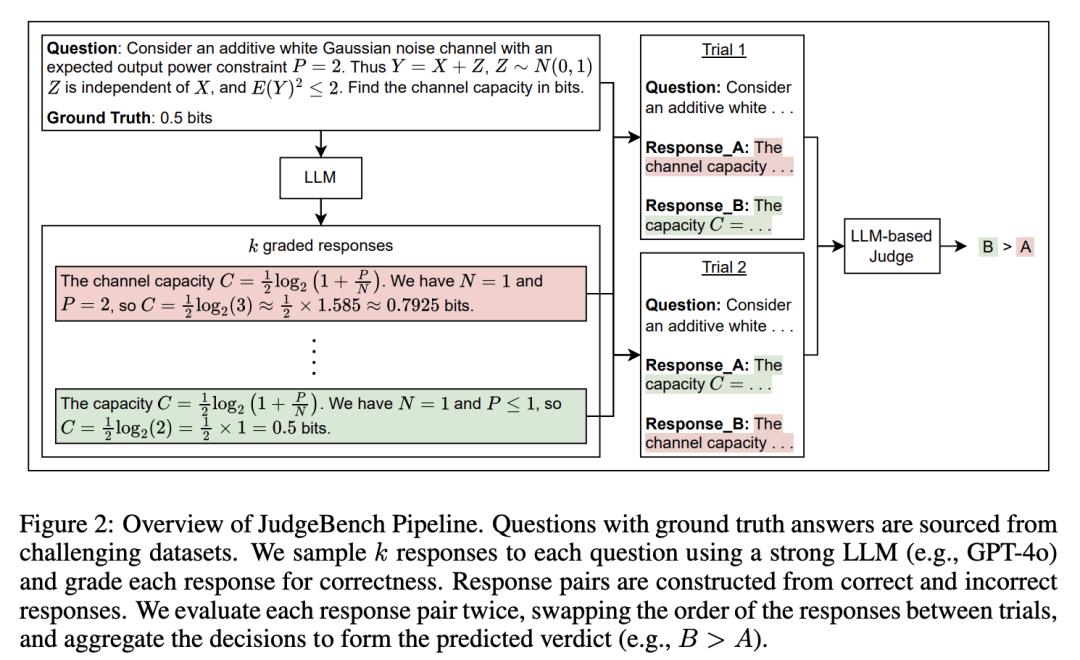
JudgeBench:用于评估“LLM 法官”的评测基准
基于 LLM 的法官已成为人类评估的一种可扩展的替代方法,并越来越多地被用于评估、比较和改进模型。然而,基于 LLM 的法官本身的可靠性却很少受到审查。随着 LLM 越来越先进,它们的回答也越来越复杂,需要更强的法官来评估它们。现有基准主要侧重于法官与人类偏好的一致性,往往无法解释更具挑战性的任务,因为在这些任务中,众包的人类偏好并不能很好地反映事实和逻辑的正确性。
为了解决这个问题,来自加州大学伯克利分校和圣路易斯华盛顿大学的研究团队提出了一个新颖的评估框架来客观地评估基于 LLM 的法官。在此框架基础上,他们提出了 JudgeBench,这是一个用于评估基于 LLM 的法官在知识、推理、数学和编码等方面的挑战性回答对的基准。
JudgeBench 利用新颖的管道将现有的困难数据集转换成具有挑战性的回答对,并使用反映客观正确性的偏好标签。他们对一系列提示法官、微调法官、多智能体法官和奖励模型进行了全面评估,结果表明 JudgeBench 比以前的基准测试提出了更大的挑战,许多强模型(如 GPT-4o)的表现仅略高于随机猜测。总体而言,JudgeBench 为评估日益先进的基于 LLM 的法官提供了一个可靠的平台。
论文链接:
https://arxiv.org/abs/2410.12784
GitHub 地址:
https://github.com/ScalerLab/JudgeBench
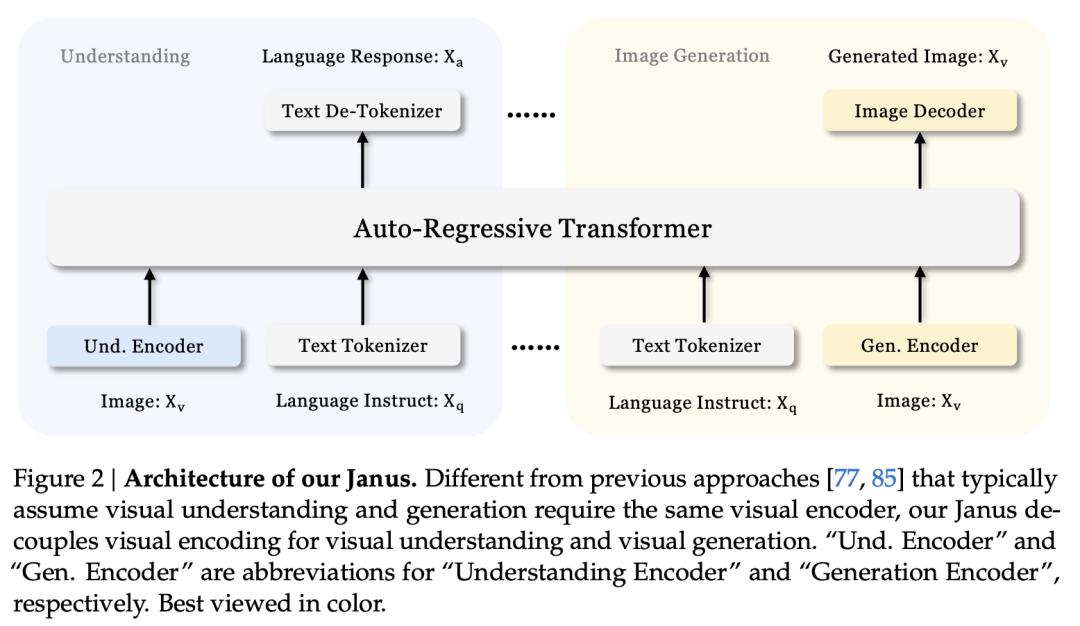
DeepSeek 推出统一多模态理解、生成自回归框架 Janus
来自 DeepSeek 和香港大学的研究团队提出了 Janus,一个统一多模态理解和生成的自回归框架。之前的研究通常依赖单一的视觉编码器来完成这两项任务,如 Chameleon。然而,由于多模态理解和生成所需的信息粒度不同,这种方法可能导致性能不理想,尤其是在多模态理解方面。
为了解决这个问题,他们将视觉编码解耦为不同的路径,同时仍然利用单一、统一的 Transformer 架构进行处理。这种解耦不仅缓解了视觉编码器在理解和生成中的角色冲突,还增强了框架的灵活性。例如,多模态理解和生成组件可以独立选择最合适的编码方法。
实验表明,Janus 超越了以往的统一模型,并达到或超过了特定任务模型的性能。Janus 的简单性、高度灵活性和有效性使其成为下一代统一多模态模型的有力候选者。
论文链接:
https://arxiv.org/abs/2410.13848
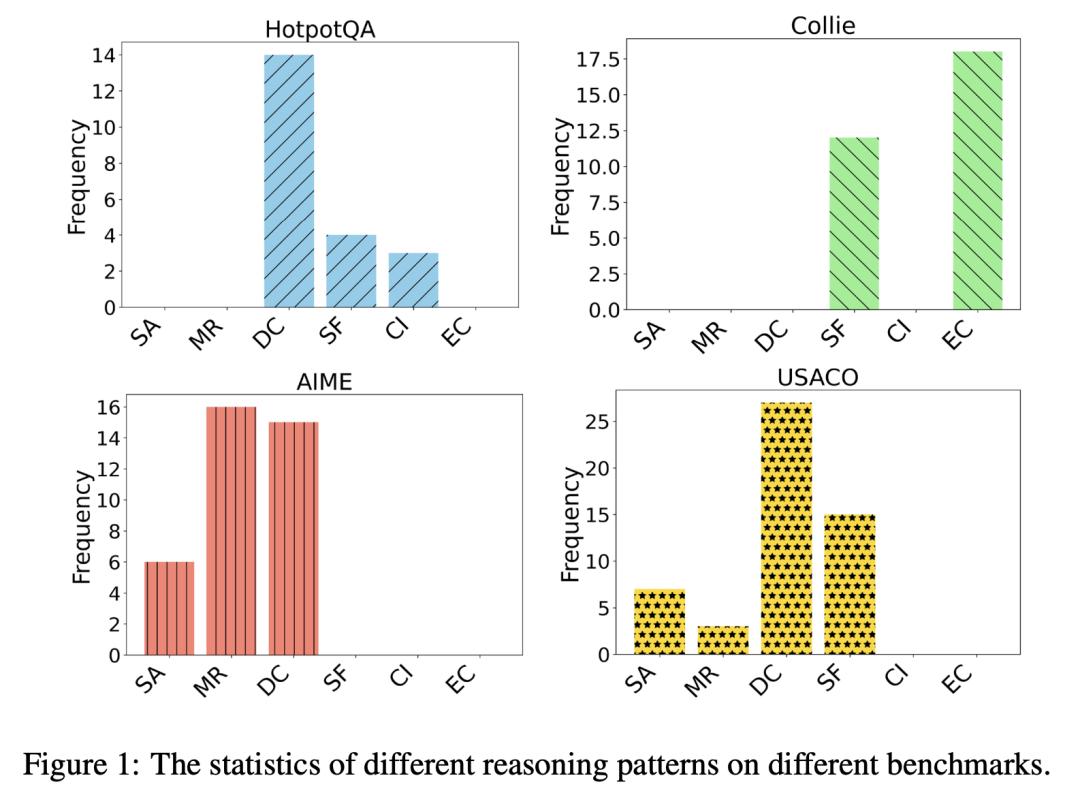
OpenAI o1 模型推理模式的比较研究
使大语言模型(LLM)能够处理更广泛的复杂任务(如编码、数学等)、 编码、数学)引起了许多研究人员的极大关注。随着 LLM 的不断发展,仅仅增加模型参数的数量所带来的性能提升越来越小,计算成本也越来越高。最近,OpenAI 的 o1 模型表明,推理策略(即 Test-time 计算方法)也能显著增强 LLM 的推理能力。然而,这些方法背后的机制仍有待探索。
在这项工作中,来自 M-A-P 和中国科学院大学的团队及其合作者为研究 o1 的推理模式,以 OpenAI 的 GPT-4o 为骨干,在三个领域(即数学、编码、常识推理)的一般推理基准上比较了 o1 与现有的 Test-time 计算方法(BoN、Step-wise BoN、Agent Workflow 和 Self-Refine)。
具体来说,首先,他们的实验表明,o1 模型在大多数数据集上都取得了最佳性能。其次,对于搜索不同响应的方法(如 BoN),他们发现奖励模型的能力和搜索空间都限制了这些方法的上限。第三,对于将问题分解为多个子问题的方法,由于特定领域的系统提示可以规划出更好的推理过程,因此 Agent Workflow 比 Step-wise BoN 取得了更好的性能。第四,值得一提的是,他们总结了 o1 的六种推理模式,并对几个推理基准进行了详细分析。
论文链接:
https://arxiv.org/abs/2410.13639
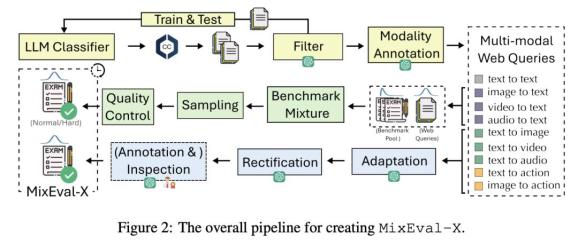
首个“任意对任意”的真实世界多模态评估基准
感知和生成不同的模态对于人工智能模型有效地学习和接触真实世界的信号至关重要,因此需要可靠的评估来促进其发展。来自新加坡国立大学的研究团队及其合作者发现目前的评估存在两个主要问题:(1) 标准不一致,不同社区制定的协议和成熟度各不相同;(2) 存在严重的查询、分级和泛化偏差。
为了解决这些问题,他们提出了 MixEval-X,这是首个“任意对任意”的真实世界基准,旨在优化和标准化不同输入和输出模态的评估。他们提出了多模态基准混合和适应性校正管道,以重建真实世界的任务分布,确保评估有效地通用于真实世界的使用案例。
广泛的元评估表明,他们的方法能有效地将基准样本与真实世界的任务分布对齐。同时,MixEval-X 的模型排名与众包真实世界评估的排名密切相关(高达 0.98),而且效率更高。
论文链接:
https://arxiv.org/abs/2410.13754
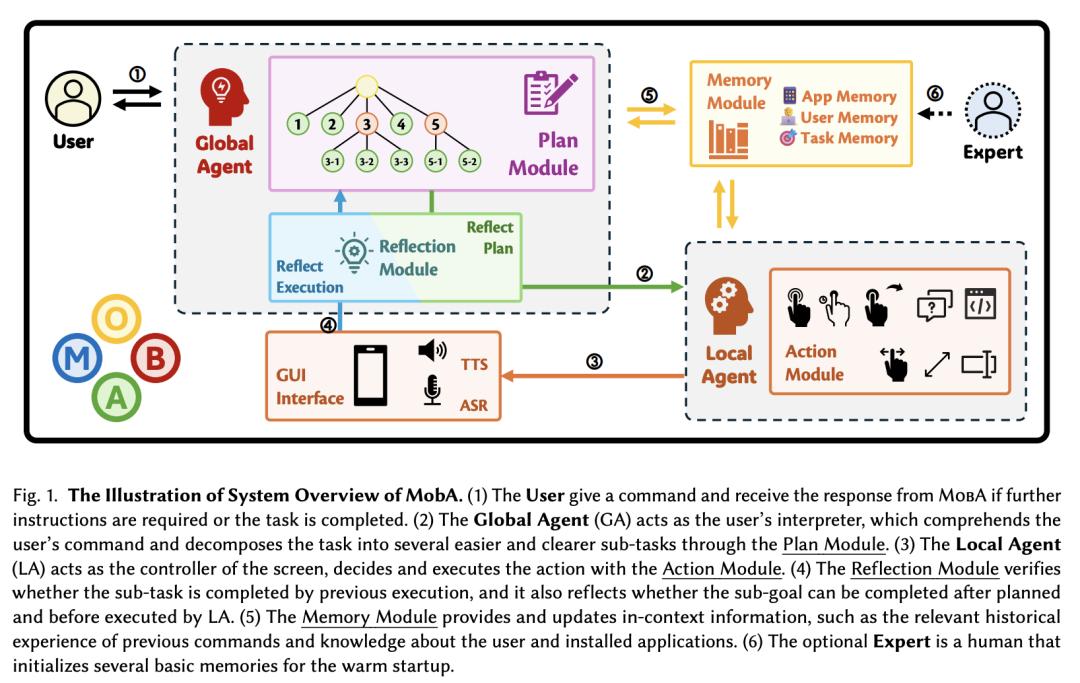
上交大团队推出 MobA:由多模态大语言模型驱动的新型移动智能体
当前的移动助手受限于对系统 API 的依赖,或因理解和决策能力有限而难以应对复杂的用户指令和多样化的界面。为了应对这些挑战,上海交通大学团队提出了 MobA,一种由多模态大语言模型驱动的新型移动智能体,通过复杂的两级智能体架构增强理解和规划能力。
高级全局智能体(GA)负责理解用户指令、跟踪历史记忆和规划任务。低级局部智能体(LA)在子任务和来自 GA 的记忆的指导下,以函数调用的形式预测详细行动。集成反思模块可以高效地完成任务,并使系统能够处理以前从未见过的复杂任务。在实际评估中,MobA 在任务执行效率和完成率方面都有显著提高,这突出表明了由 MLLM 驱动的移动助手的潜力。
论文链接:
https://arxiv.org/abs/2410.13757